Machine Learning on DOTA 2 Statistics
DOTA 2 is a heavily played game, with 640,227 average players in June of 2016.1 Recently, I had the chance to do an independent study at the University Of Missouri - Kansas City looking at the YASP Dota 2 Dataset2. I tried to answer two different questions: How accurately could one predict which team will win based on their initial choices of heroes, and how does the number of resources acquired at different times in the game affect the likelihood of winning?
Reason For Doing This Project
I am not someone who regularly plays DOTA 2. I have many friends that do and there exist a large community and public data. I think this made it a good choice for a machine learning project since I have minimal domain-specific knowledge and the data was widely accessible. Additionally, having people who are interested in the results and like to chat about the project made gathering knowledge easier than something like a finance or crime project.
Dataset and Filters
For a dataset, I initially looked at the YASP 3.5 Million Data Dump3 but ended up mostly using the YASP December 2015 500k Data Dump4 since it was smaller and easier to deal with. I filtered the data by removing games where the there were less than 10 human players and none of the players had leaver status. 5 This was done to remove some variance from the data while still preserving a wide range of games. Unlike most other projects doing similar things, I did not filter out games in the low skill bracket.
Accuracy of Prediction in Games given GPM6 and XPM7 History To That Minute
This question explores what the link between resource acquisition history and accuracy of predicting a user. DOTA 2 is largely considered a resources game, a paper found that they could predict the winner or loser with 99.58% accuracy by looking at GPM and XPM after a game. 8 The model was built by looking at the history of the GPM and XPM at every minute up to a specific minute, and then built a logistic regression model off of that history and then tried to predict the outcome of the game. Each model used 5000 samples and was validated against 10 fold cross validation. These samples weren’t necessarily the same 5000 samples since it takes the first 5000 samples where the game is long enough to contain that many minutes, so a 40-minute game wouldn’t be considered at 60 minutes.
The model’s vectors are
Xt=radiant_gold_advantage_at_t_minutes
X(t+max_time)=radiant_xp_advantage_at_t_minutes
Y = 1 if radiant won, 0 otherwise.
T is a particular minute of the game, and max_time is the maximum amount of time considered.
Graph
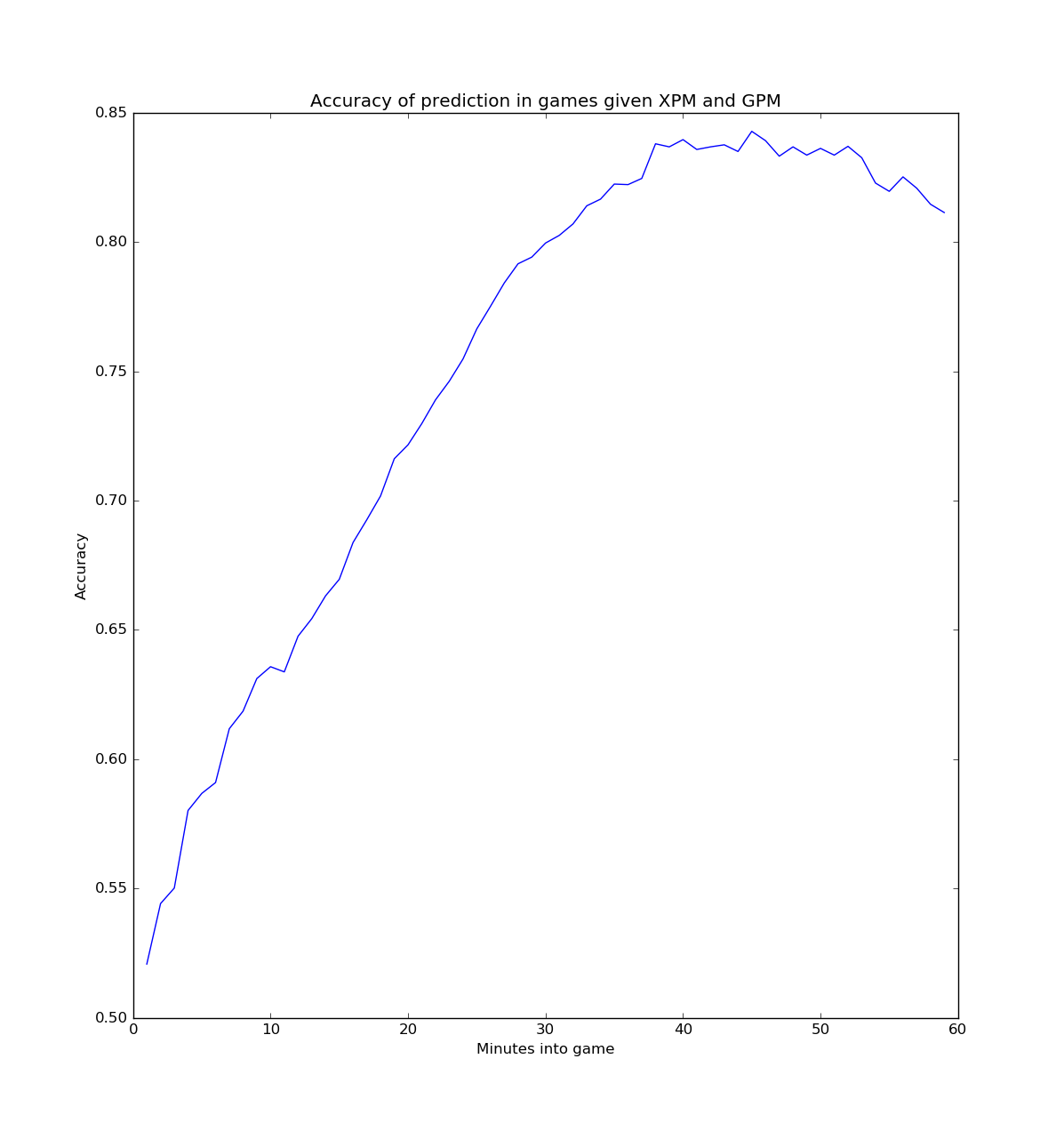
There appears to be a fairly linear relationship with prediction accuracy and minutes into the game until you get to about 30 minutes into the game when it starts to level off. This could hint that the first 30 minutes of the game are the most important in terms of resources.
Predicting Win/Loss Using Initial Hero Picks
Besides resources, team composition and hero picks are another important factor in determining the success a team has with a DOTA 2 match. I used a few different models which were trained on the following vectors
Xi = 1 if heroID i was in the match on radiant side, 0 otherwise
X(i+113) = 1 if heroID i was in the match on dire side, 0 otherwise
Y = 1 if radiant won, 0 otherwise
which leads to a classification problem. This vectorization and one of the models was taken from Kevin Technlology9. The number 113 was chosen because there are 113 heroIDs in DOTA 2. There may have been fewer heroes in the dataset I considered, but constant 0s shouldn’t have an affect on the output.
Models
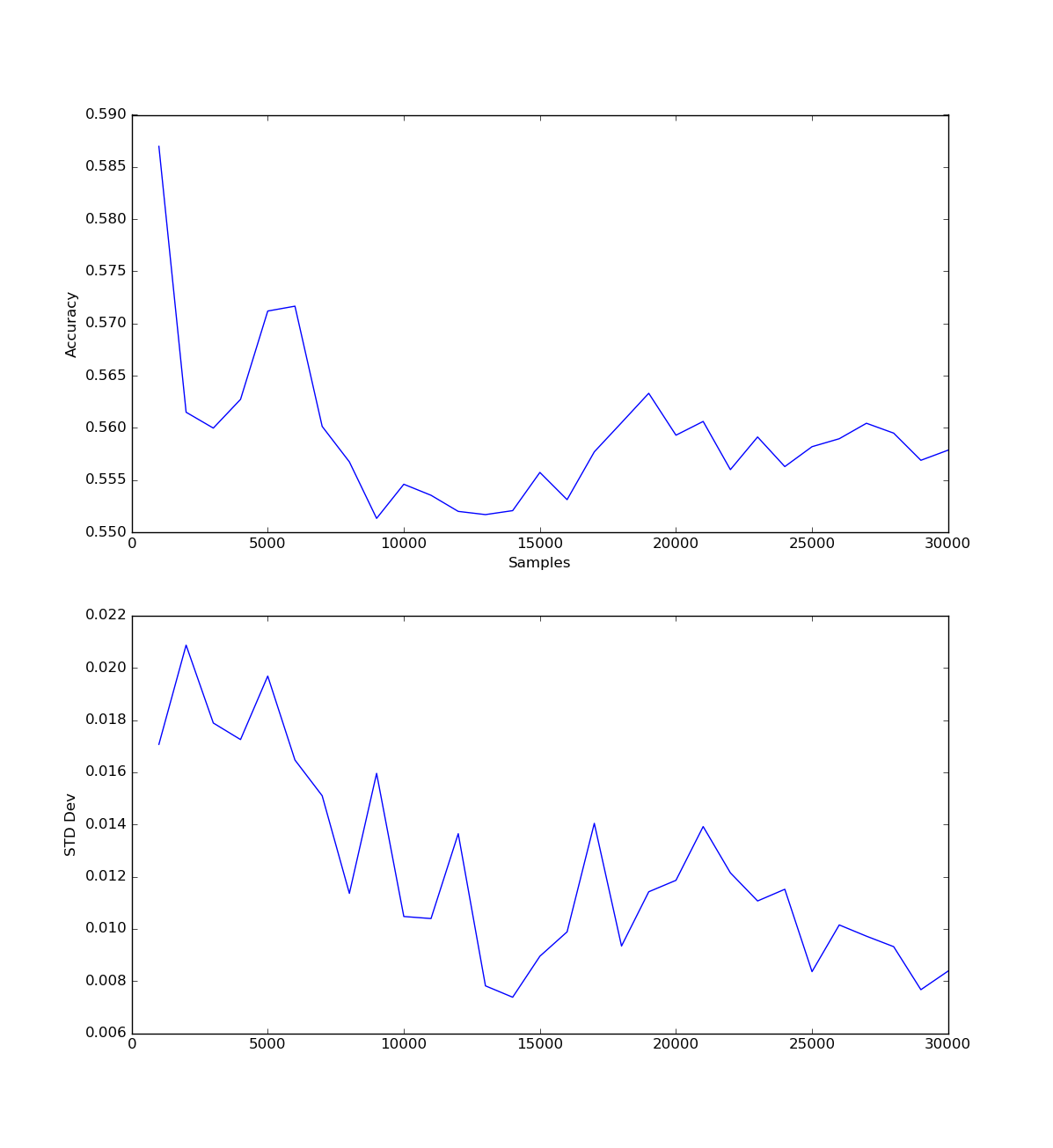
Logistic Regression
Logistic Regression performed fairly well and was very quick to train. I used most of the SKlearn defaults for LogisticRegression but changed the number of jobs for the fitting routine to match the number of cores I wanted to use. 10
The following graph shows the accuracy of predicting a game given the feature vector with the number of samples, as well as the standard deviation.
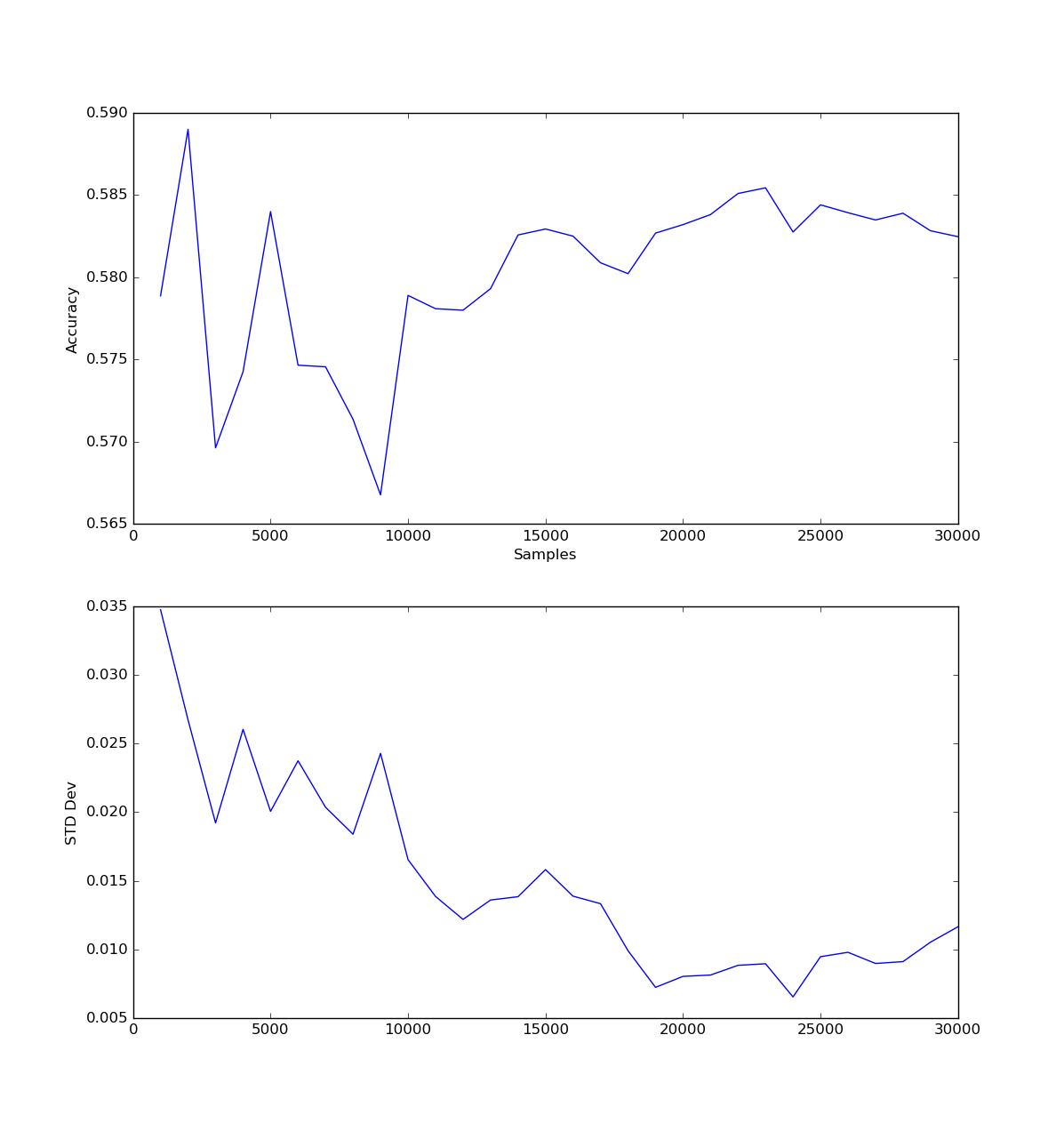
Accuracy was slightly higher with lower samples, but plateaus again at about 2500 samples, with a lower standard deviation. The sharp spikes at the beginning suggest to me that the model was undertrained and happened to ‘get lucky’ on the data it encountered.
K-Nearest Neighbors
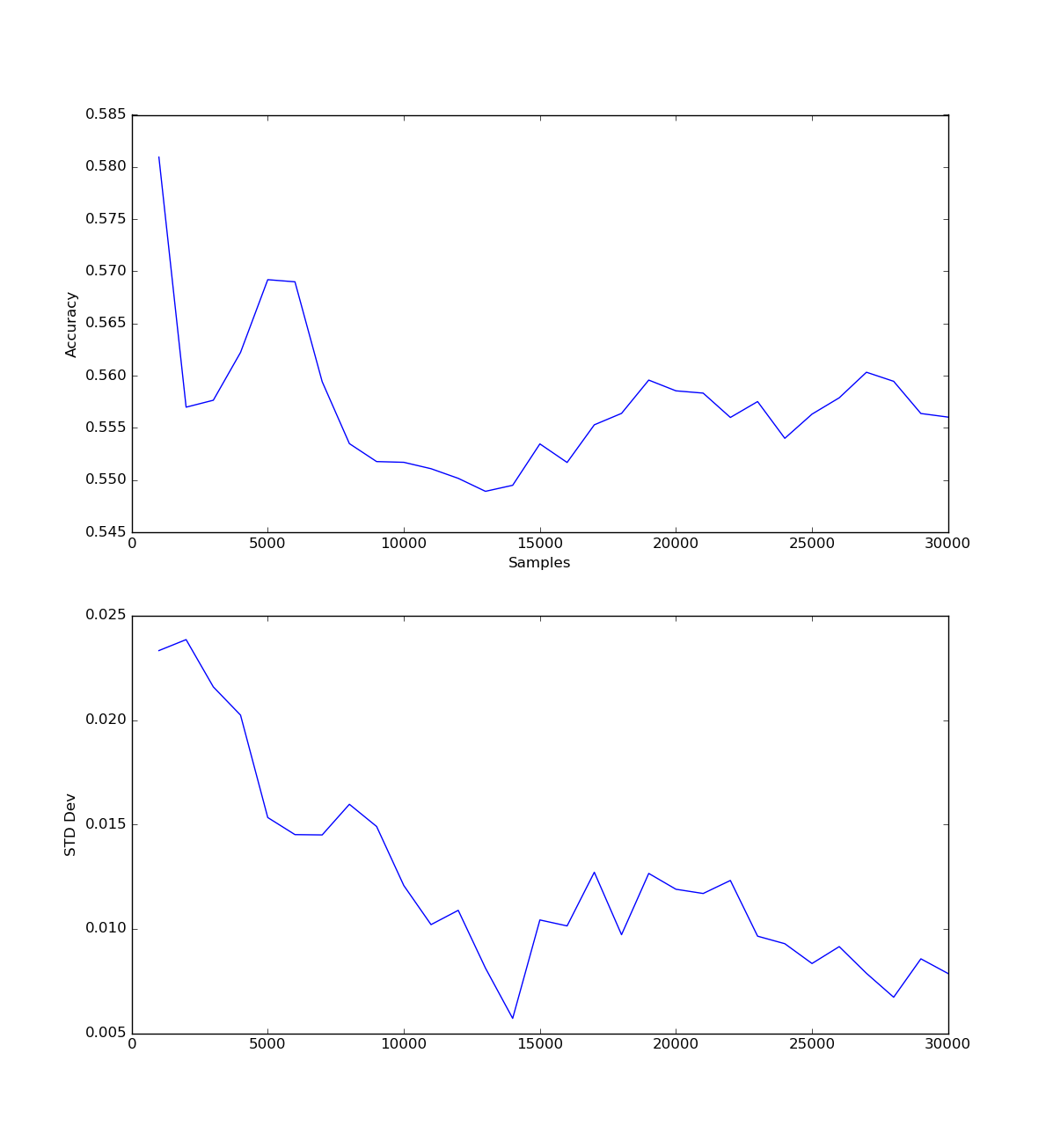
I tried K-Nearest Neighbors a few different ways with varying results. KNN also has a parameter of K, which needed to be found for every model, but turned out to be about 48 for each. Because there was a high factor space with a relatively low number of models, KNN did not perform as well as it could.
K-Nearest Neighbours, Sklearn Default Settings
I ran a program which would find the optimal number of neighbours on 5000 samples, which peaked around 48
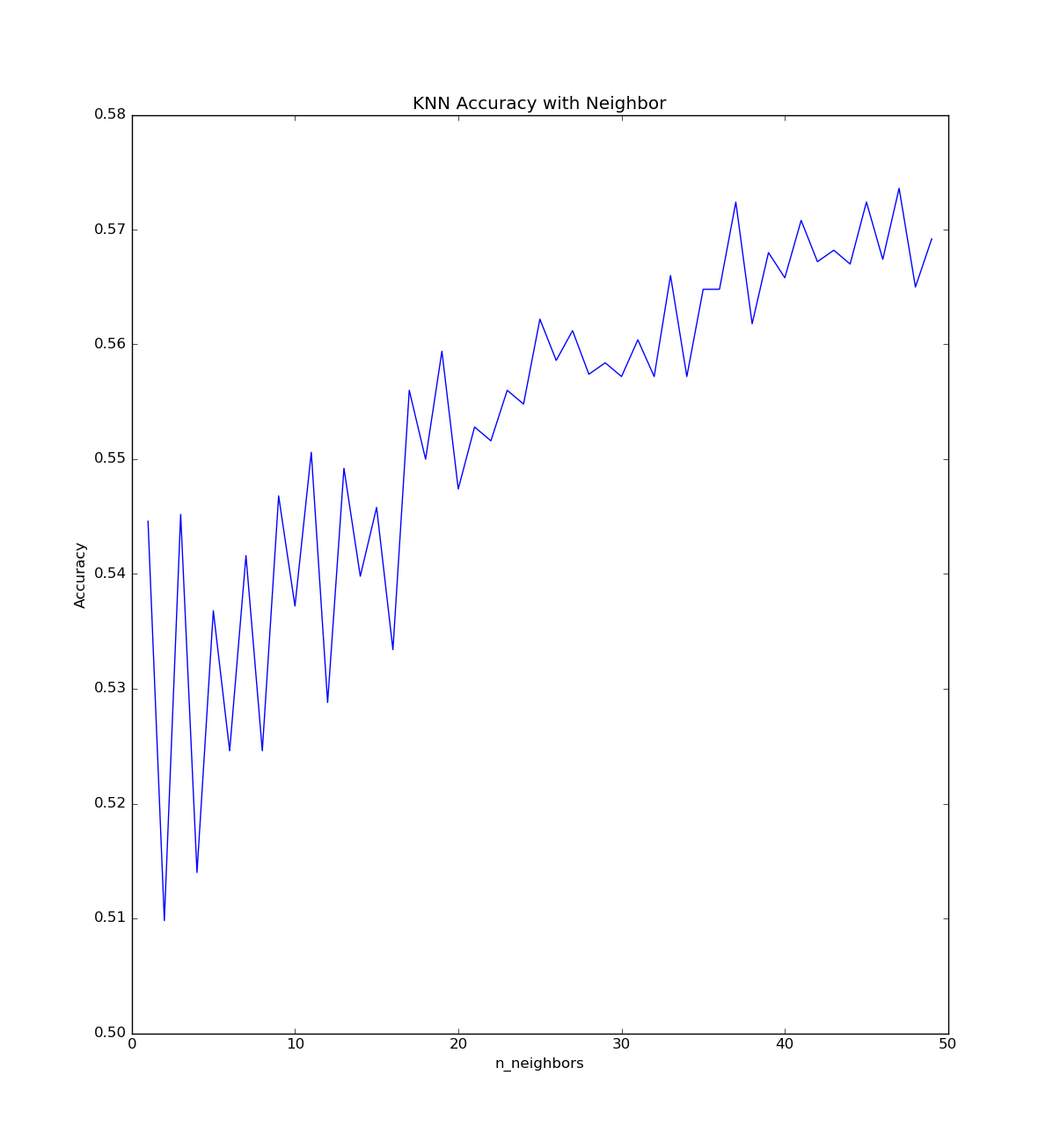
After finding the optimal number of neighbours, I looked at how it would perform with different numbers of samples
K-Nearest Neighbours, Distance Weighting
SKlearn has an optional weights11 parameter which controls how much weight each neighbour has. Setting this to ‘distance’ weights points according to how far away they are and provided a boost in accuracy. This is probably because the factor space is too big for the number of samples, so matches which are far away are getting considered too heavily without a weighting metric.
Looking at neighbours versus accuracy for this model gives a similar graph as the non-weighted version.
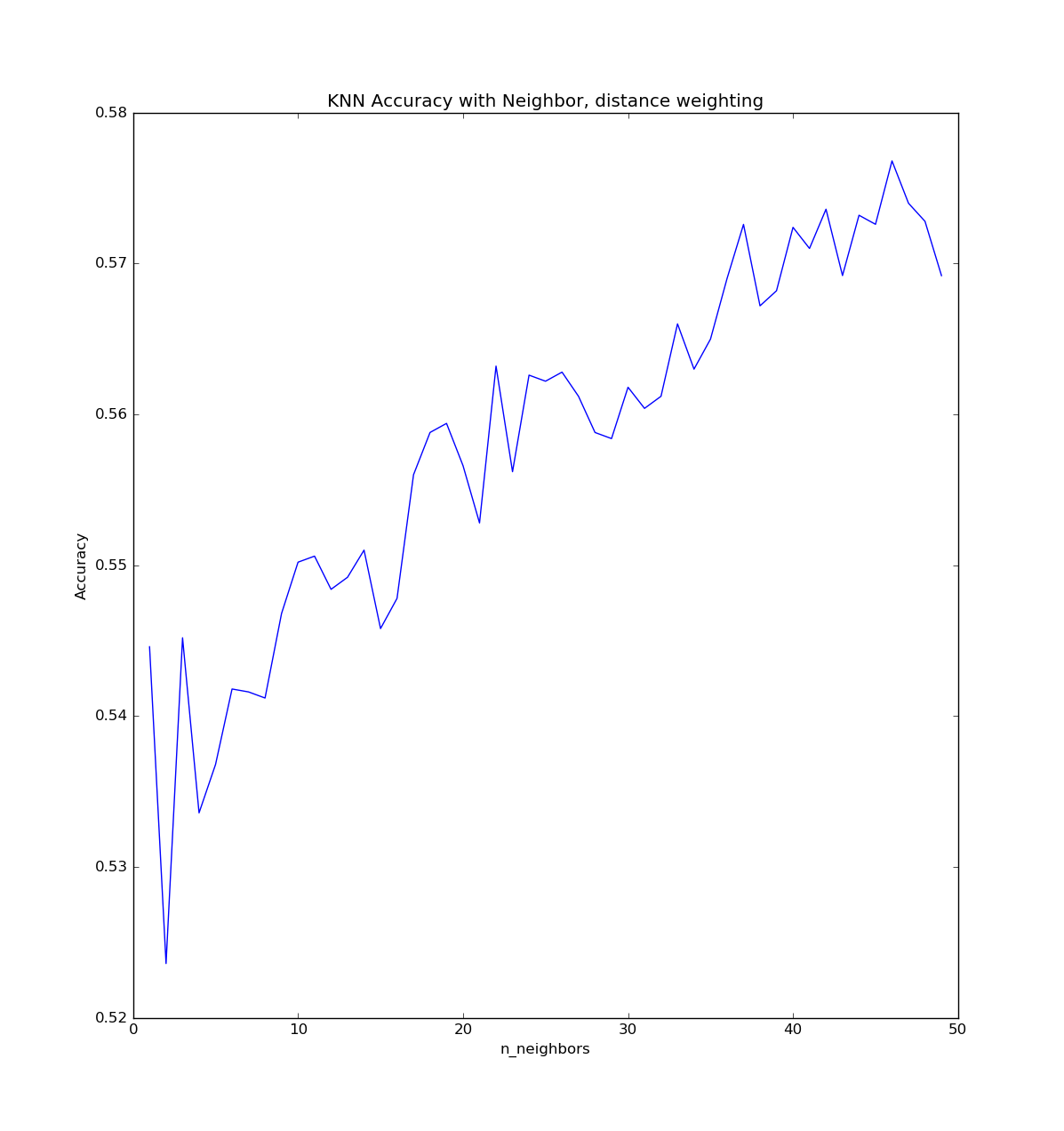
In terms of accuracy with a number of samples, it performs slightly better than unweighted, but not as good as Logistic Regression.
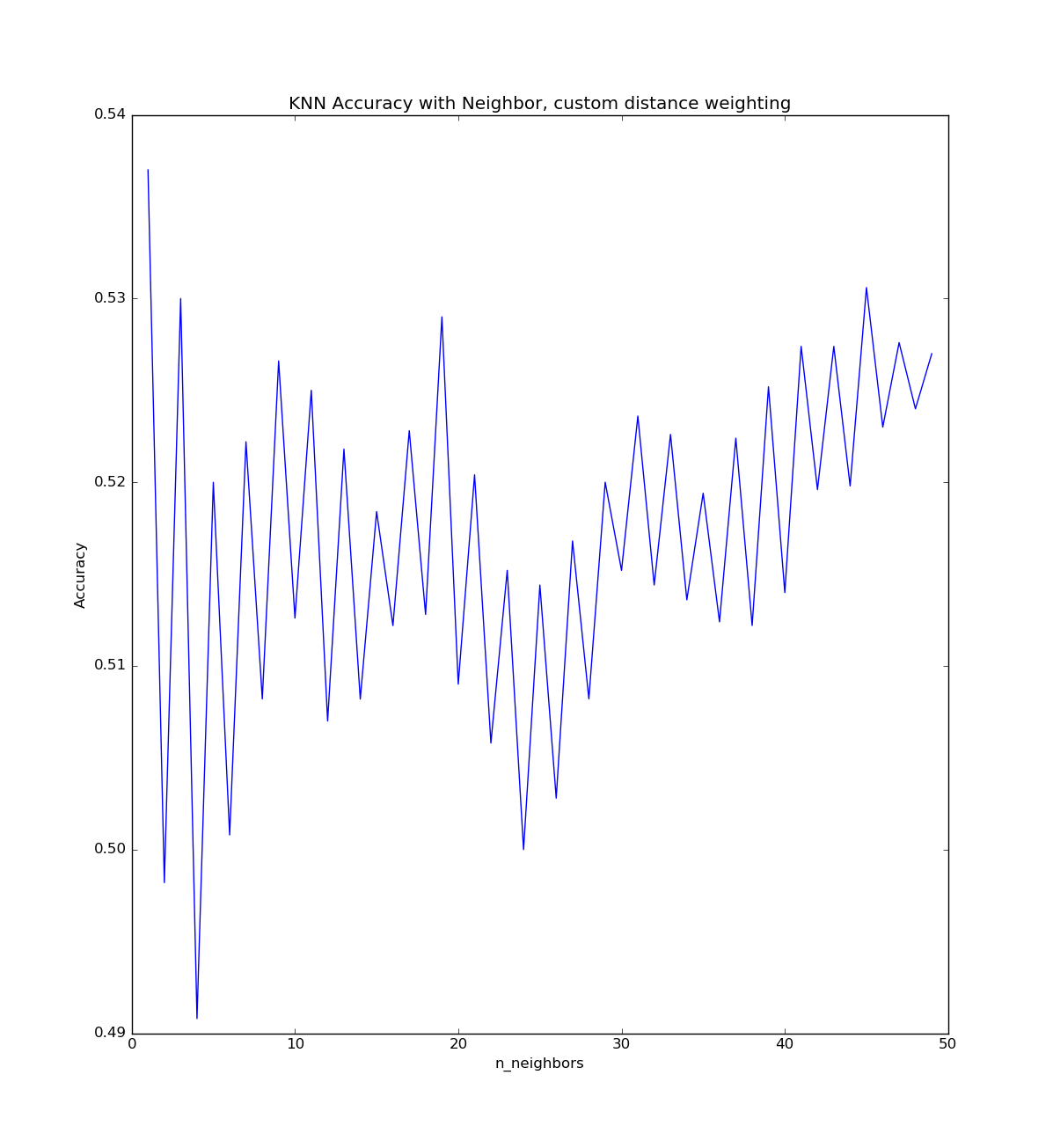
K-Nearest Neighbours, Kevin Technologies Custom Weighting and Distance Metric
Kevin Technology reported improvements using a custom weighting function described here I tried to replicate their work, but I could not get any good results, as shown in the following graph. This may very well be a result of me implementing it wrong, or that they are only training on high skill games.
Neural Networks
I tried to implement a Neural Network because I believed it would do well in a high factor space and consider hero relationships well, but I couldn’t get any results above 53% accuracy, probably because I only have a very basic understanding of them. Exploring Neural Networks could be a project for the future.
Tools Used
Special Thanks
Professor Eddie Burris - Helping me and overseeing the project
Nathan Walker - Consulting with me and providing domain specific knowledge
Code Listing
Note: This does not show all of the things shown in this post simply because I would change things around and overwrite the file.
#hero_picker.py
from sknn.platform import gpu64
from setup_data import *
from sklearn.linear_model import LogisticRegression
from progress.bar import Bar
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
import matplotlib.pyplot as plt
from sknn.mlp import Classifier, Layer
def construct_hero_matrix_and_win_vector(number=1000):
def construct_hero_row(): #Ordering is 113 radiant heros followed by 113 dire(?) heros
return [0 for i in range(113*2)] # there are 113 ids
rows = []
radiant_wins = []
idx = 0
bar = Bar('Processing ' + str(number), max=number)
for obj in make_json_stream(number, lambda a: a['picks_bans'] and a['human_players'] == 10 and all(map(lambda b: b['leaver_status'] == 0,a['players'])) and a['game_mode'] == 2):
cur_row = construct_hero_row()
bar.next()
for pick_ban in obj['picks_bans']:
if(pick_ban["is_pick"]):
cur_row[pick_ban['hero_id'] + 113 * pick_ban['team']] = 1 #Set the hero id to 1 to indicate selection, and if the team is 1 (i think dire) then add 113 to it
assert(sum(cur_row) == 10)
rows.append(cur_row)
if(obj['radiant_win']):
radiant_wins.append(1)
else:
radiant_wins.append(0)
bar.finish()
return (rows,radiant_wins)
def custom_distance(vec1,vec2):
return np.sum(np.logical_and(vec1,vec2))
def custom_weighting(distances):
d = 4 #From website
weights = np.power(np.multiply(distances[0],0.1),d)
return np.array([weights])
def run_knn_finding_n_neighbors():
max_accuracy_and_neighbor = (-1,-1)
neighbors = []
accuracies = []
bar = Bar("KNN Building",max=50)
rows, wins = construct_hero_matrix_and_win_vector(5000)
rows = np.array(rows)
wins = np.array(wins)
for i in range(44,50):
bar.next()
cvs = cross_validate(KNeighborsClassifier(n_neighbors=i,n_jobs=-1, metric=
custom_distance,weights=custom_weighting), rows, wins)
if(cvs.mean_accuracy > max_accuracy_and_neighbor[0]):
max_accuracy_and_neighbor = (cvs.mean_accuracy,i)
accuracies.append(cvs.mean_accuracy)
neighbors.append(i)
bar.finish()
print("Max accuracy " + str(max_accuracy_and_neighbor[0]) + " with n_neighbors " + str(max_accuracy_and_neighbor[1]))
plt.plot(neighbors,accuracies)
plt.ylabel("Accuracy")
plt.xlabel("n_neighbors")
plt.title("KNN Accuracy with Neighbor, custom distance weighting, custom weight")
plt.show()
def neural_network():
x,y = construct_hero_matrix_and_win_vector(5000)
x = np.array(x)
y = np.array(y)
nn = Classifier(layers=[Layer("Rectifier", units=226),Layer("Softmax")],
learning_rate=0.02, n_iter=100)
print('score =', cross_validate(nn,x,y).mean_accuracy)
#model = KNeighborsClassifier(n_neighbors=48,n_jobs=-1,weights='distance')
model = LogisticRegression(n_jobs=-1)
construct_accuracy_with_sample_size_plots(model,construct_hero_matrix_and_win_vector,1000,30)
# setup_data.py
import json
from sklearn import cross_validation
import matplotlib.pyplot as plt
import numpy as np
def make_json_stream(max=None,json_filter=None):
f = open('./yasp-dump-2015-12-18.json')
idx = 0;
for jsonline in f:
try:
if(json_filter):
obj = json.loads(jsonline)
if(json_filter(obj)):
yield obj
idx += 1
else:
yield json.loads(jsonline)
idx += 1
if(idx == max):
return
except json.decoder.JSONDecodeError:
pass
class CVResults:
r2 = 0
r2_std_dev = 0
mean_accuracy = 0
accuracy_std_dev = 0
accuracy = 0
mse = 0
mse_std_dev = 0
def cross_validate(model,x,y):
results = CVResults()
scores = cross_validation.cross_val_score(model, x, y, cv=10)
results.accuracy = scores
results.mean_accuracy = scores.mean()
results.accuracy_std_dev = scores.std()
return results
def construct_accuracy_with_sample_size_plots(model,generator,delta,number):
samples = []
accuracies = []
std_devs = []
rows,results = generator(delta*number)
rows = np.array(rows)
result = np.array(results)
for i in range(1,number + 1):
print("Running size " + str(delta * i))
samples.append(delta * i)
cvs = cross_validate(model, rows[:delta * i],result[:delta * i])
accuracies.append(cvs.mean_accuracy)
std_devs.append(cvs.accuracy_std_dev)
plt.title("Accuracy of Prediction with Sample size")
ax1 =plt.subplot(211)
plt.plot(samples,accuracies)
plt.ylabel("Accuracy")
plt.xlabel("Samples")
plt.subplot(212,sharex=ax1)
plt.ylabel("STD Dev")
plt.plot(samples,std_devs)
plt.show()
#accuracy_xpm_gpm.py
from setup_data import *
from progress.bar import Bar
def construct_xp_gold_at_time_delta(deltas,count=1000):
rows = []
radiant_wins = []
bar = Bar('Processing',max=count)
for obj in make_json_stream(count, lambda a: a['human_players'] == 10 and all(map(lambda b: b['leaver_status'] == 0, a['players'])) and len(a['radiant_gold_adv']) >= deltas and len(a['radiant_xp_adv']) >= deltas):
rows.append(obj['radiant_gold_adv'][:deltas] + obj['radiant_xp_adv'][:deltas])
if obj['radiant_win']:
radiant_wins.append(1)
else:
radiant_wins.append(0)
bar.next()
bar.finish()
return (rows,radiant_wins)
def accuracy_over_time():
deltas = []
accuracy_results = []
for minute in range(1,60):
rows,wins = construct_xp_gold_at_time_delta(minute,5000)
if(rows == [] or wins == []):
break
model = LogisticRegression()
results = cross_validate(model,rows,wins)
deltas.append(minute)
accuracy_results.append(results.mean_accuracy)
print("With " + str(minute) + " minute accuracy is " + str(results.mean_accuracy) +", std dev: "+str( results.accuracy_std_dev))
plt.plot(deltas,accuracy_results)
plt.ylabel("Accuracy")
plt.xlabel("Minutes into game")
plt.title("Accuracy of prediction in games given XPM and GPM")
plt.show()
accuracy_over_time()
Update January 8, 2017: I recieved an email saying the code didn’t run. I changed it so it hopefully does now.
-
http://steamcharts.com/app/570 ↩
-
https://yasp.co/ ↩
-
http://academictorrents.com/details/5c5deeb6cfe1c944044367d2e7465fd8bd2f4acf ↩
-
http://academictorrents.com/details/384a08fd7918cd59b23fb0c3cf3cf1aea3ea4d42 ↩
-
http://dev.dota2.com/showthread.php?t=105752 The best explanation of leaver status I could find. ↩
-
Gold Per Minute, Gold is be used to buy items to power up a player’s hero. http://dota2.gamepedia.com/Gold ↩
-
Experience Per Minute, Experience is used to build a hero to be stronger and learn new abilities. http://dota2.gamepedia.com/Experience ↩
-
http://cseweb.ucsd.edu/~jmcauley/cse255/reports/fa15/018.pdf Page 6, Table 1 ↩
-
http://kevintechnology.com/post/71621133663/using-machine-learning-to-recommend-heroes-for Many techniques for captains pick lifted from here. ↩
-
http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html ↩
-
http://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html ↩